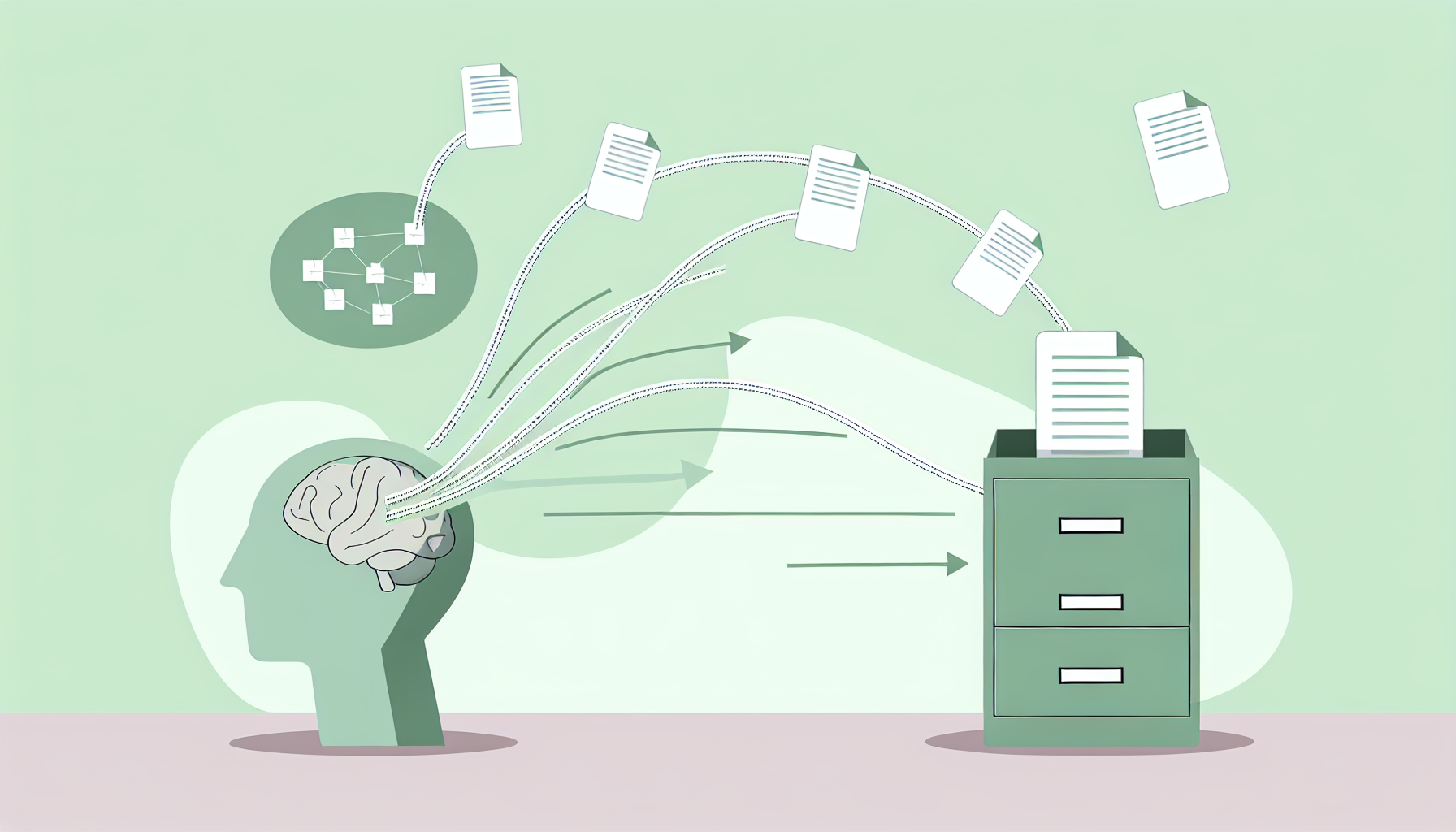
Un LLM comme Claude a été entraîné sur des données publiques jusqu’à une certaine date. Il ne connaît pas vos documents internes, vos procédures, vos données clients. Le RAG résout ce problème.
Le problème : l’IA ne sait pas tout
Si vous demandez à Claude « Quel est le processus de remboursement chez notre entreprise ? », il ne peut pas répondre. Il n’a jamais vu votre documentation interne.
La solution : RAG
RAG = Retrieval-Augmented Generation. Le principe : avant de poser la question au LLM, on cherche dans vos documents les passages pertinents, et on les injecte dans le prompt. Le LLM répond alors en s’appuyant sur vos données.
Comment ça marche concrètement
1) Vos documents sont découpés en morceaux (chunks). 2) Chaque morceau est transformé en vecteur numérique (embedding). 3) Ces vecteurs sont stockés dans une base vectorielle (Pinecone, Weaviate, ChromaDB). 4) Quand l’utilisateur pose une question, on cherche les morceaux les plus proches et on les envoie au LLM avec la question.